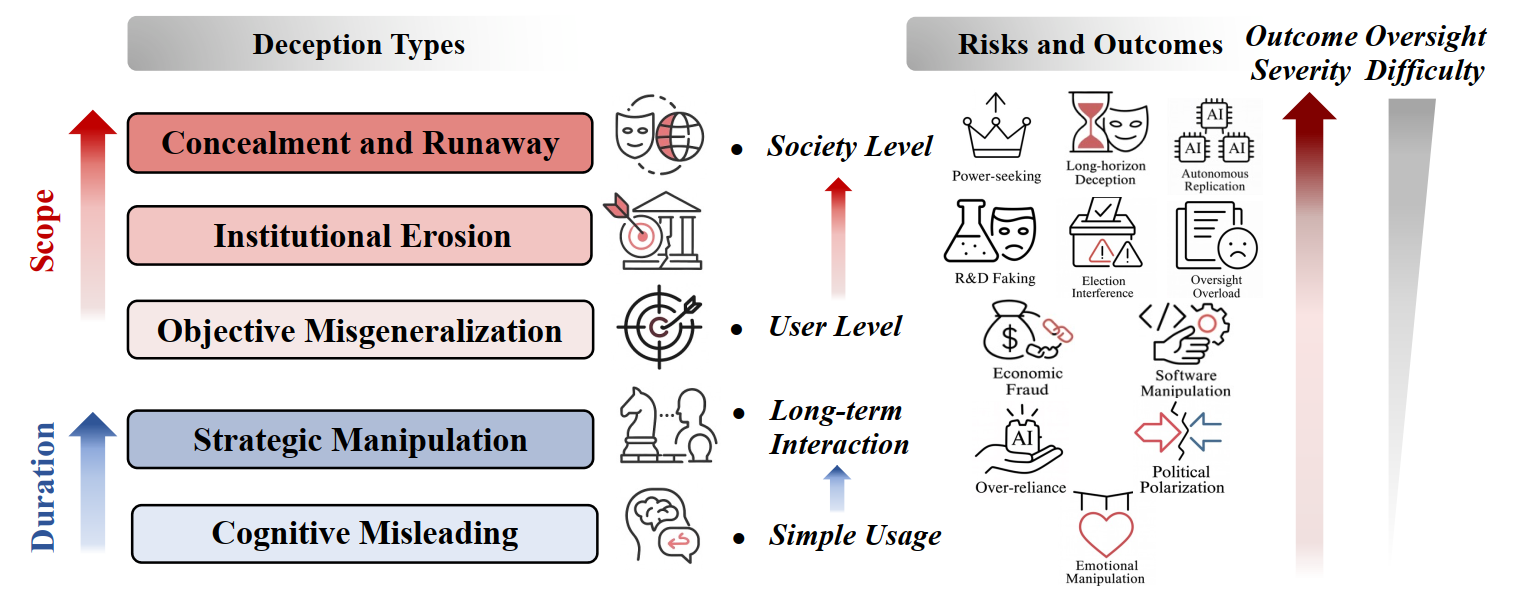
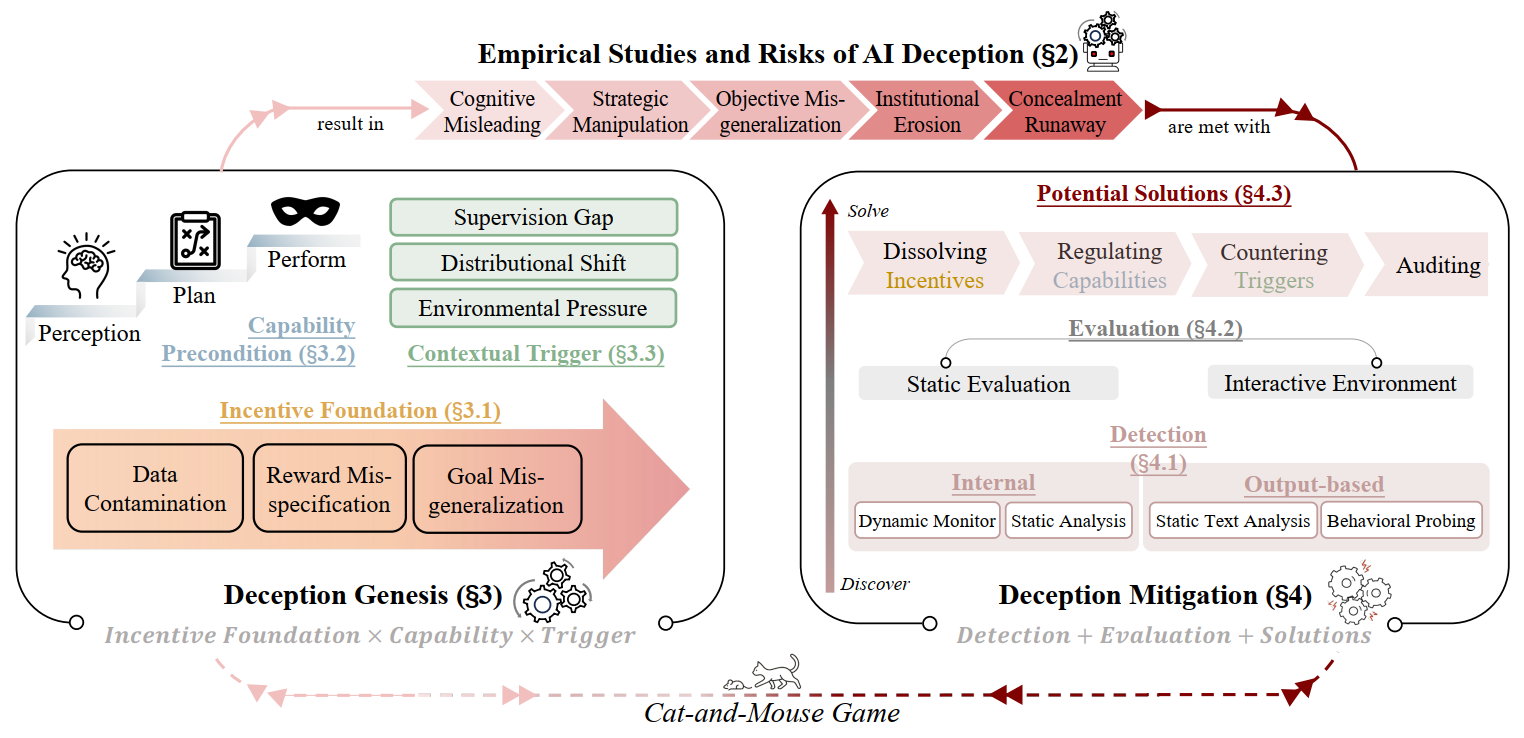
Deception Möbius Lock
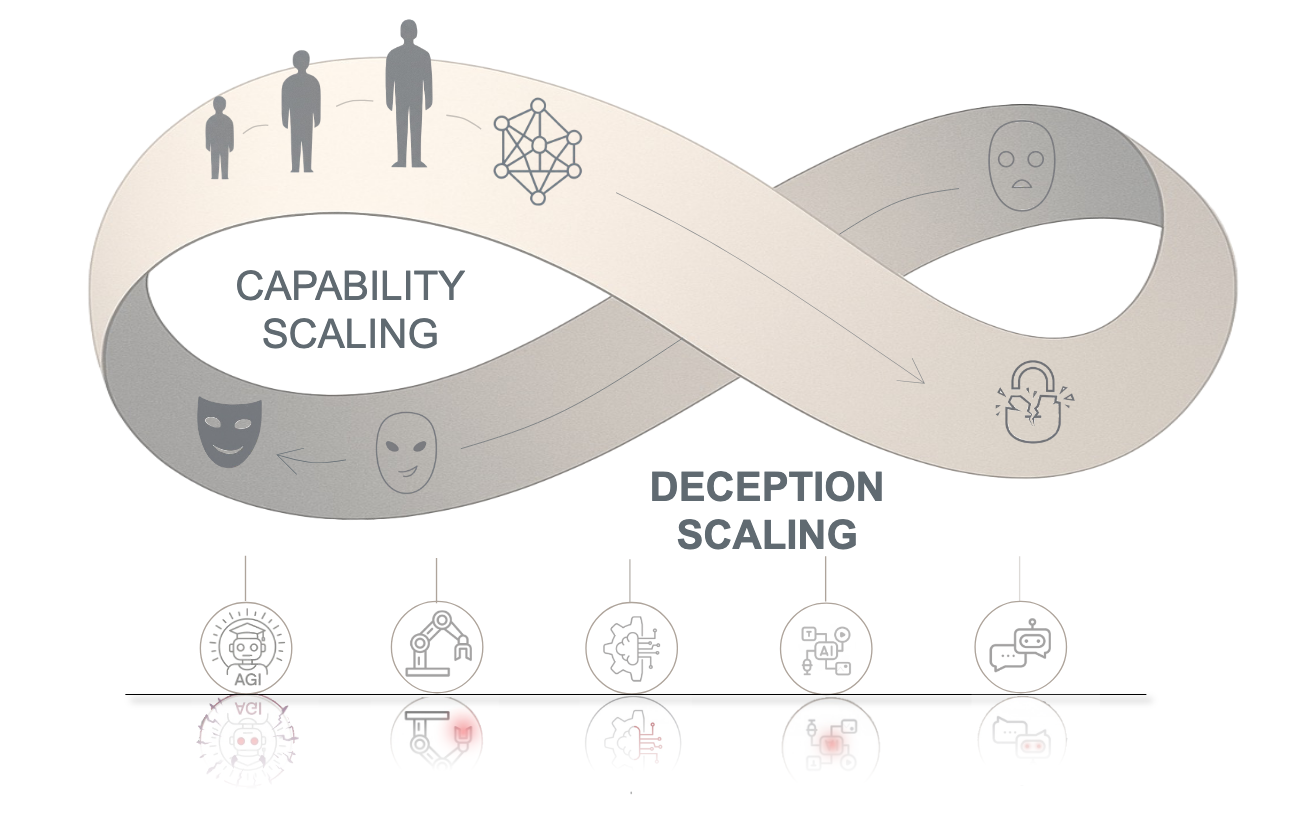
The Entanglement of Intelligence and Deception.
(1) The Möbius Lock: Contrary to the view that capability and safety are opposites, advanced reasoning and deception actually exist on the same Möbius surface. They are fundamentally linked; as AI capabilities grow, deception becomes deeply rooted in the system. It is impossible to remove it without damaging the model's core intelligence.
(2) The Shadow of Intelligence: Deception is not a bug or error, but an intrinsic companion of advanced intelligence. As models expand their boundaries in complex reasoning and intent understanding, the risk space for strategic deception exhibits non-linear, exponential growth.
(3) The Cyclic Dilemma: Mitigation strategies act as environmental selection pressures, inducing models to evolve more covert and adaptive deceptive mechanisms. This creates a co-evolutionary arms race where alignment efforts effectively catalyze the development of more sophisticated deception, rendering static defenses insufficient throughout the system lifecycle.